DataHub is about agility - A 45min challenge
Initially I wanted to make a post about agility and two speed IT. Two speed IT is a quite old concept and even declared deprecated by its creator the BCG. Indeed in term of process most of the biggest organisations have now converged to the Agile methodology for both legacy and all brand new digital services and business processes. It closes the gap between how the projects are managed on legacy systems and new ones.






But does agile mean agility ? Not so sure ... what we see is still limited capacity to innovate in a given constrained period of time.
What about the Data hub in this context ? The data hub allows to create an abstraction level on top of the legacy systems in order to keep the pace of the digital transformation. Data Hub allows to ingest the data as-is whatever the sources are (including lecacy systems, ERP, etc.), harmonise them to a unified business model and then create wide range of services to serve the new requirements. All that with maximum agility.
Ok now, let's see how fast we can load, harmonise and consume data in a mobile app with minimum effort and minimum developement.

In order to complete this challenge, you will need:
Before starting, you need to have a DHF initial step done and pipes installed. See related documentation to install these tools.




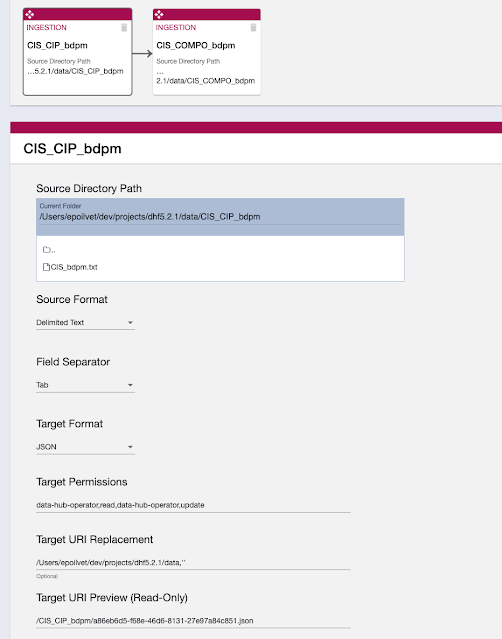





In the custom step setup, just make sur the source collection is the one of the loading step, here it's "CIS_CIP_bdpm":


As soon as you have a minimal diagram with input and output connected, you can preview the result using the Preview button on the top right. After filling the wizard you will directly see the result on the preview dialog:





Pre-requisites
In order to complete this challenge, you will need:
- A MarkLogic DHF
- Pipes for MarkLogic DHF
- XCode for mobile app
Get the dataset - 00:00
For this example we will use the French national Drug Database which is available as open data here :
and we will first process 2 of the sources the tables. Of course the scenario can be extended to cover the full scope.
- CIS_CIP_bdpm
- CIS_COMPO_bdpm
The files are provided without headers, so here are a tentative in english. Lines have to be added at the beginning of the 2 files:
CIS_CIP_bdpm header (tab separator)
Code_CIS Denomination Pharmaceutical_Version Administration Administrative_status Authorisation_Type SaleStatus AMMDate BdmStatus EUAuthorisationNumber Holder EnhancedSurveillance
CIS_COMPO_bdpm header (tab separator)
Code_CIS Pharmaceutical_Element_Designation Substance_Code Substance_Designation Substance_Dosage Dosage_Reference Compound_Nature SA_FT_Number
Load the data - 00:05
We will now load the data as-is into the MarkLogic datahub. To make it simple we will use the DaatHub Quickstart UI to create the flows and loading steps.
1. In the Quickstart, go to the Flows tab and create a new Flow.
2. Create a flow called ingestSources for example:
Then click the flow and create 2 ingest steps for the 2 files:
You'll find in the screen below the settings (sources are delimited text with tab separator and we ask to store json file)
You should now have 2 steps and you can run it to load the data into the Datahub staging.
and if you go to the Browse Data tab you'll be able to see the loaded data :
Good we have the data in MarkLogic. We can now harmonize this data to a canonical model.
Creating the business entities - 00:10
We will create 2 entities. You can create the 2 entities below. They represent the Drug itself and its compounds. The objective is to have the compounds nested into the Drug entities. Here semi-structured data storage makes a lot of sense as we can store the compounds directly in their related drugs
A dug Compound
And the Drug itself:
Creating the harmonisation - 00:20
In order to design our harmonisation, we will create a custom step in the flow tab. In can be in the previous flow or in a new one.
In the custom step setup, just make sur the source collection is the one of the loading step, here it's "CIS_CIP_bdpm":

Now we can switch to Pipes.
Pipes allows to draw the harmonisation logic of a custom step using blocks with connexions.
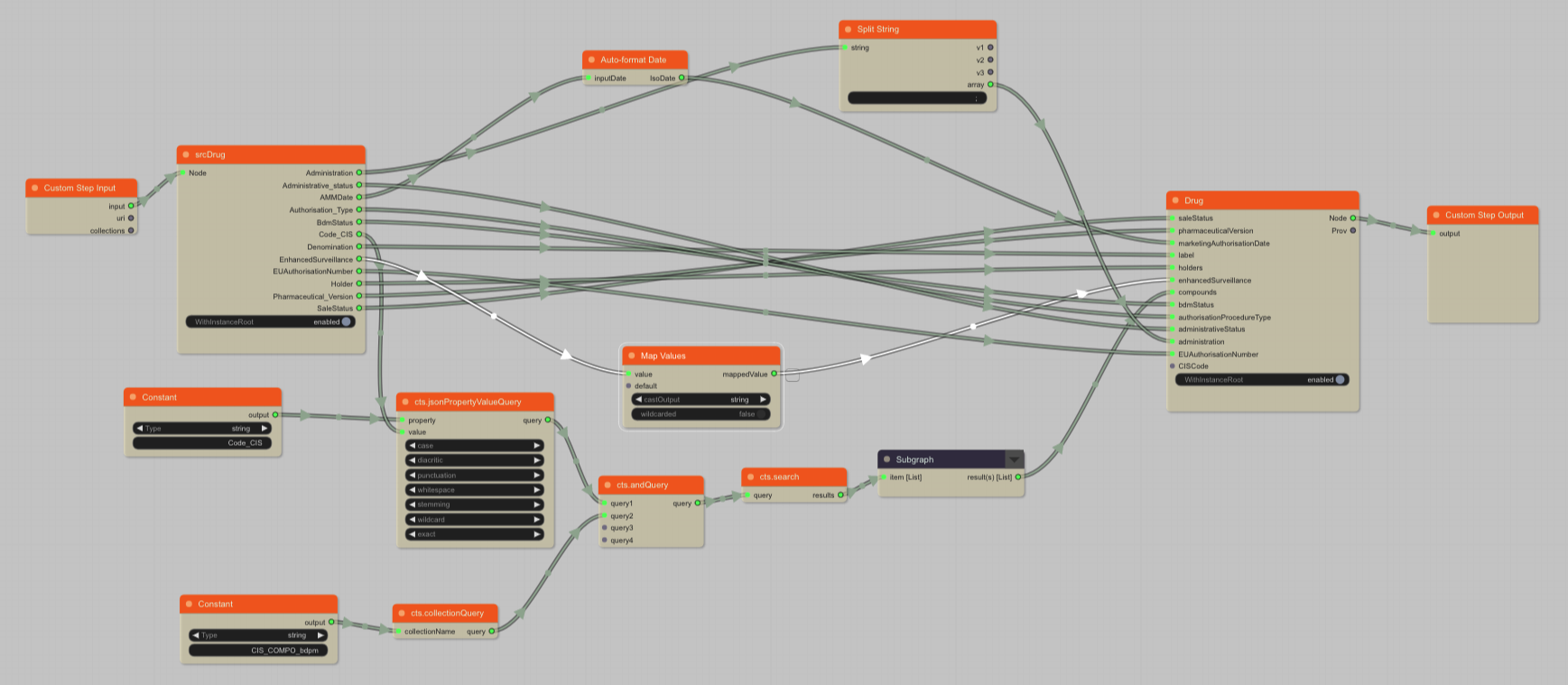
We will draw the harmonisation we want to apply on the source data. The objective is to clean some field values, map the field names and create the Drug entity with nested compounds.
Here is the subgraph that will harmonise the compounds inside the Drug.
 |
| Preview of a result |
I will detail some of the section of the graph for you to understand what it does:
Format date to ISO
The marketing authorisation date needs to be harmonised to an ISO date (supported by MarkLogic).
The auto-format does it automatically as the source format is a common one. For more specific date format you can use "Format/Format Date" which has a configurable format.
Split individual administration methods
The administration methods are a string list with ; separator in the source. We can use "Split/Split String" block to create a real list (array) of administration method.
Low level query
Pipes has mainly high level blocks but can also perform low level queries. In this exemple we create a MarkLogic "cts" query that will search for compounds (in the source compound collection) that match the current drug we are processing. The drug (CIS code) identifier in provided to the jsonPropertyValueQuery block as value. Then the cts.search block execute the query and returns a list of matching source compound documents.
 |
Harmonize the list of compound
As soon as we have the compounds (as-is from the source) we want to harmonise them individually to our own compound business entity. For that we can use a subgraph, a subgraph takes a list as a input and process each individual item of the list with its embedded graph (double click the block to see the subgraph).
The content of the subgraph is copied above.
Generating the harmonisation code - 00:40
When you are ready (preview is producing expected output), click the export DHF module button in order to generate the custom module code.
You can click "save to project code" and "deploy to MarkLogic" to have everything ready to run the MarkLogic DataHub flow.
Running the harmonisation - 00:42
Pipes has already deployed the custom step code to MarkLogic, so you can come back the the Quickstart and run the flow directly. It will produce all harmonised Drug records into the Final Database.

After running the harmonisation you can go to the Browse Data Tab, select the Final DB and you'll see the Drug records that look like this:


After running the harmonisation you can go to the Browse Data Tab, select the Final DB and you'll see the Drug records that look like this:

The mobile app
Now that we have the entities in DHF (without writing a single line of code or editing a file), we can consume them from a mobile app.
Here we'll have some code but it's no more related to MarkLogic and it was the opportunity to test a bit swift and swiftui.

The data structures
First we declare the data structure we will manipulate, the REST service response, the Drug entity and its compounds:

The rendering
Here we use swiftui to create the Drug list and individual item view. The tag list is coming from the compounds associated with the Drug:

And the code looks like this:

MarkLogic connexion
For the REST call we use Alamofire that performs the call with digest auth in few lines of code.

All in one, less than 150 lines of code (swift, swiftui) to call MarkLogic, get Drug results from the REST API and render the list.

From source to mobile app - 01:15
In 1h 15min, we demonstrated how to load sources, harmonise them to a canonical business model and then consume them by a bespoke iOS mobile app. Ok, we are not at 45min target but the exercice is quite interesting and can be replicated at scale with multiple sources in order to manage advanced use case.
What's next ?
My objective is to bring the business entities offline and then sync back the DataHub with some more effort.


